
This week’s session of the History of the Book seminar at the Taylor Institution delved into the intersection of traditional manuscript study and digital encoding. Building on the introduction by Emma Huber, the session opened with an engaging overview of how XML’s TEI (Text Encoding Initiative) standard provides a framework for scholars to represent texts in a structured, machine-readable way. TEI allows editors to encode not only words on a page, but also the materiality of historical documents – marginalia, corrections, scribal marks, and even traces of printing. Such precision enables digital editions to reflect the layered realities of historical sources and opens up new avenues for analysis and sharing as well as providing accessibility.

The second part of the seminar shifted from theory to practice. It was very exciting to have students experimenting with two preparatory tasks in order to get familiar with the structure of TEI. With the help of Emma Huber, students first had to solve a little puzzle, organising snippets of code to form a correct syntax to recreate the theoretical framework in order to encode two stanzas of Shakespearean poems. Students were then invited to try their hand at encoding texts themselves – using the Oxygen XML Editor – either working with a sample NHS card or a sixteenth-century Lutheran pamphlet. Those who opted for the latter (as most did) used Luther’s already encoded Wider die mordischen vnd reubischen Rotten der Pawren (Arch. 8°. G. 1525(27)) as a framework, preserved and edited as part of the digital Taylor Editions.
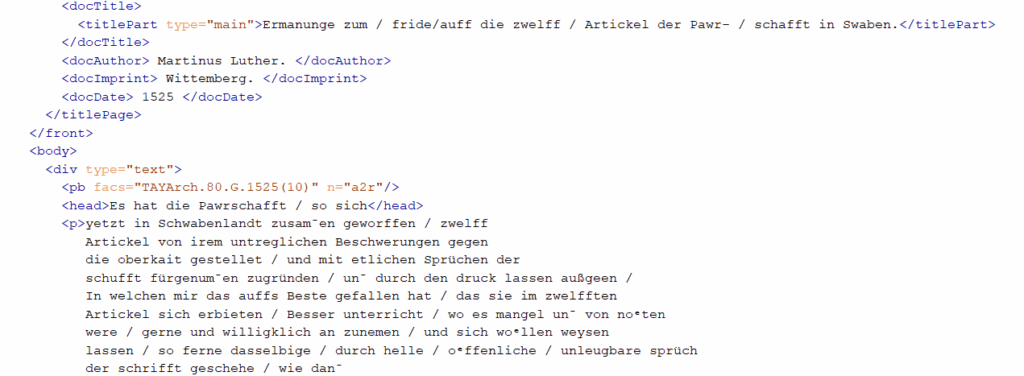
Within the XML file, tags capture bibliographic details, editorial notes, and links to digital facsimiles. Students in class could then simply reuse the existing XML tags to start working on their own pamphlets (a list of all Reformation pamphlets in the Taylorian), for instance the not yet digitalised Ermanunge zum fried auff die zwelff Artickel der Pawrschafft in Swaben (Arch. 8°. G. 1525(10)). Apart from a few challanges – for example deciphering certain words or especially line breaks within the manuscript – it was an intensive but quite straightforward process. As can be seen in the exemplary image below, the Middle High German text is added in a normalised form in a <p> (paragraph) tag. This process would then be repreated for each abstract. Finally, the normalised text would be translated into English, peer-reviewed and published as a Taylorian Edition.
The possibilities when encoding with XML are to a certain degree endless as there are not really any immediate boundaries, at least concerning manuscripts. Even beginners – as us students were – can get familiar with XML’s TEI standard very quickly.
To sum that up, the session was an experimental but also incredibly effective way to work with both manuscripts and one of the most common digital tools when encoding manuscripts. Also, it was possible to once again engage with manuscripts, which is always the best part for us literature students. Many thanks to Emma Huber and Henrike Lähnemann for the hands-on introduction to XML and the enormous help while students attempted to decipher certain parts of the manuscripts. Perhaps, a few of us students will be from this stage onwards more and more invested into Digital Humanties, trying out other programmes and digital approaches for our own repective research projects.